The defense will take place on 27th February at 09:00, salle de conférences du bâtiment 507, rue du Belvédère, 91400 Orsay.
Sign languages are an essential means of communication for deaf communities. Sign languages are visuo-gestual languages using the modalities of hand gestures, facial expressions, gaze and body movements. They possess rich grammar structures and lexicons that differ considerably from those found among spoken languages. The uniqueness of transmission medium, structure and grammar of sign languages requires distinct methodologies.
The performance of automatic translations systems between high-resource written languages or spoken languages is currently sufficient for many daily use cases, such as translating videos, websites, emails and documents. On the other hand, automatic translation systems for sign languages do not exist outside of very specific use cases with limited vocabulary. Automatic sign language translation is challenging for two main reasons. Firstly, sign languages are low-resource languages with little available training data. Secondly, sign languages are visual-spatial languages with no written form, naturally represented as video rather than audio or text.
To tackle the first challenge, we contribute large datasets for training and evaluating automatic sign language translation systems with both interpreted and original sign language video content, as well as written text subtitles. Whilst interpreted data allows us to collect large numbers of hours of videos, original sign language video is more representative of sign language usage within deaf communities. Written subtitles can be used as weak supervision for various sign language understanding tasks.
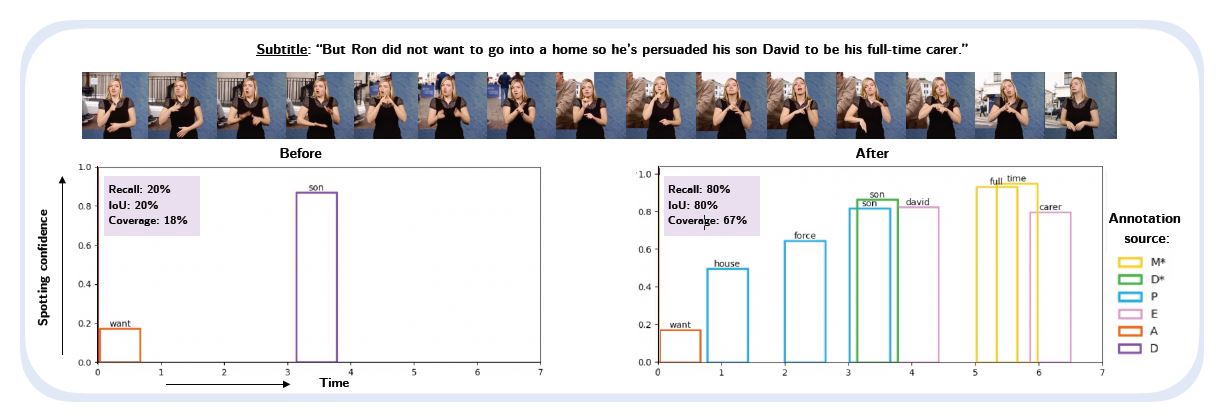
To address the second challenge, we develop methods to better understand visual cues from sign language video. Whilst sentence segmentation is mostly trivial for written languages, segmenting sign language video into sentence-like units relies on detecting subtle semantic and prosodic cues from sign language video. We use prosodic cues to learn to automatically segment sign language video into sentence-like units, determined by subtitle boundaries. Expanding upon this segmentation method, we then learn to align text subtitles to sign language video segments using both semantic and prosodic cues, in order to create sentence-level pairs between sign language video and text. This task is particularly important for interpreted TV data, where subtitles are generally aligned to the audio and not to the signing. Using these automatically aligned video-text pairs, we develop and improve multiple different methods to densely annotate lexical signs by querying words in the subtitle text and searching for visual cues in the sign language video for the corresponding signs.