Presse, Sciences et Technologies des langues
Créer éthiquement des textes artificiels pour entraîner les intelligences artificielles du domaine biomédical
Publié le
Le traitement automatique des langues vise à créer des outils de traitement d’énoncés écrits, parlés ou signés pour diverses applications, et le domaine biomédical est l’un des domaines d’application majeur de l’intelligence artificielle. Pour être entraînés et évalués, les modèles de langue nécessitent un très grand nombre de textes. Dans le domaine biomédical, de tels outils permettraient notamment la classification ou la reconnaissance de séquences. À titre d’exemple, en partant du parcours de santé d’un patient, le TALTraitement Automatique des langues permettrait de déterminer si ce patient est un fumeur et dans quelle proportion.
« Pour le traitement automatique des langues appliqués au domaine biomédical, la difficulté est que cela impliquerait d’avoir accès aux textes qui contiennent des données confidentielles sur le parcours de santé des personnes », soulève Aurélie Névéol, directrice de recherche CNRS au Laboratoire interdisciplinaire des sciences du numérique (LISN – CNRS/Université Paris-Saclay/CentraleSupélec/Inria) situé à Gif-sur-Yvette et coordinatrice du projet CoDeinE[1].
Assez logiquement, l’accès à ces textes est très encadré par la réglementation. Grâce à des partenariats avec des institutions hospitalières, et en montrant à un Comité scientifique et éthique (CSE) le bien-fondé de l’utilisation des textes, les scientifiques peuvent obtenir un corpus de textes dont tous les éléments identifiants ont été supprimés. Mais les outils de TALTraitement Automatique des langues entraînés grâce à ces données ne peuvent pas être appliqués à des textes issus d’hôpitaux non-partenaires, ni utilisés pour tester des méthodes développées par d’autres chercheurs.
« Du coup, la recherche se fait un peu en silo : chacun peut développer des méthodes et les évaluer sur les données auxquelles il a accès, mais il n’y a pas de partage possible, explique Aurélie Névéol. Donc ça limite la possibilité de comparer le fonctionnement de ces méthodes sur une diversité de textes, alors qu’on sait bien que les corpus de textes peuvent présenter des variations entre différents hôpitaux voire même entre différents services. »
C’est là qu’intervient le projet CoDeinE, démarré en 2021 et mené en partenariat avec l’Hôpital européen Georges-Pompidou (AP-HP), le Laboratoire lorrain de recherche en informatique et ses applications (Loria – CNRS/Université de Lorraine/CentraleSupélec/Inria) et le CEA-List (Laboratoire d’intégration des systèmes et des technologies). Il est financé par l’Agence nationale de la recherche (ANR), dont l’objectif est de soutenir l’excellence de la recherche et l’innovation française sur le plan national, européen et international.
CoDeinE vise à produire des textes qui puissent être librement utilisés par différents acteurs du domaine biomédical afin qu’ils puissent développer et évaluer des outils de traitement automatique des langues. Ainsi, l’équipe pluridisciplinaire d’Aurélie Névéol a exploré différentes méthodes pour générer des textes synthétiques (artificiels) qui imitent les textes cliniques réels. Pour entraîner son modèle, le projet a utilisé un type de texte appelés « cas cliniques », qui sont des descriptions de parcours de patients publiés dans la littérature médicale et donc anonymes.
« L’idée est que notre modèle de génération de textes crée des textes synthétiques ressemblant aux vrais textes en termes de formulation, de vocabulaire, de jargon, d’utilisation d’acronymes…, mais aussi qu’ils soient suffisamment pertinents sur le plan clinique, détaille la chercheuse du LISN. Tout en veillant à ce qu’ils ne soient pas réalistes au point de permettre de remonter jusqu’à un cas clinique réel utilisé pour entraîner le modèle. »
Deux approches, basées sur des modèles de langue génératifs affinés par le corpus des « cas cliniques », ont été utilisées pour générer les textes. La première consiste à laisser le modèle générer librement des textes et la deuxième à lui faire créer des textes selon des contraintes démographiques et cliniques données.
En plus de la création des textes synthétiques, le projet CoDeinE s’est également attelé à leur évaluation sous différents aspects. L’un de ces aspects, plutôt d’ordre informatique, a été de déterminer si ces « faux » textes peuvent effectivement être utilisés par des modèles de traitement automatique des langues développés pour le domaine biomédical, « ce qui marche très bien, par exemple pour les reconnaissances de séquences comme des noms de maladies, de traitements ou de médicaments », apprécie Aurélie Névéol.
Un autre aspect consiste à évaluer humainement la plausibilité des textes, tant sur le plan linguistique que clinique. Pour ce faire, l’équipe a développé un « jeu ayant un but » appelé HostoMytho. Aussi, le projet CoDeinE s’est attelé à s’assurer que les textes générés ne soient pas redondants avec les cas cliniques injectés dans le modèle pour l’entraîner. L’évaluation a également porté sur l’identification de biais genrés dans les cas cliniques générés.
Enfin, l’équipe d’Aurélie Névéol a évalué l’efficacité algorithmique des modèles développés, ce qui permet également de mesurer leur impact environnemental. « Notre projet a utilisé des « cas cliniques » mais l’objectif à terme est que nos modèles soient entraînés avec des comptes rendus cliniques, explique la scientifique du LISN. Ces documents, pour des raisons de confidentialité, ne peuvent pas sortir des hôpitaux. Donc, pour générer des textes synthétiques à partir des comptes rendus cliniques, les calculs doivent être faits à l’hôpital, et avec les moyens de calcul dont ce dernier dispose, qui sont plus limités que ceux que nous avons utilisés pour le projet CoDeinE. C’est pourquoi nous devons leur fournir le modèle le plus efficace. »
Le projet est justement désormais dans l’une de ses dernières phases : le partenaire hospitalier est en train de mettre en place, à partir de comptes rendus cliniques, les méthodes de génération de textes développées par CoDeinE. « La bonne nouvelle, c’est que nos méthodes fonctionnent, apprécie Aurélie Névéol. Mais, a priori, il faudrait beaucoup plus de textes d’affinage avec les comptes rendus cliniques qu’avec les cas cliniques. Nous allons donc chercher à expliquer cela. »
Une fois ce travail mené, et après une nouvelle étape d’évaluation, « l’idée est de réussir à avoir un corpus de textes partageables tout en démontrant, à l’aide de nos métriques, qu’il n’y a aucun risque concernant la confidentialité des données qui ont servi à affiner le modèle de génération », conclu la coordinatrice du projet : « À mon sens, ce qui a fait la réussite du projet et nous a permis d’arriver à ces résultats, c’est le caractère pluridisciplinaire de l’équipe. »
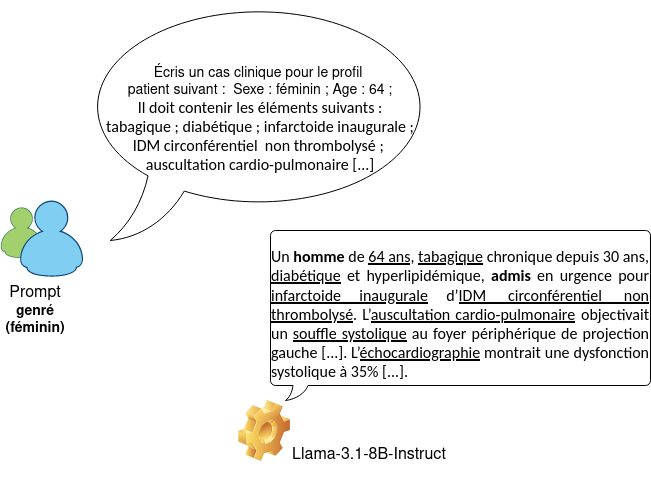
Exemple d’invite (prompt) et de cas clinique généré par un modèle de langue affiné. Dans le texte généré, les éléments en gras représentent les termes automatiquement répérés pour inférer le genre de la personne décrite. Les éléments soulignés représentent les contraintes démographiques et cliniques utilisées pour guider la génération d’un cas clinique par le modèle. On observe que la contrainte de genre (“femme”) n’a pas été respectée. © Fanny Ducel
[1] Création éthique de données textuelles artificielles : Synthèse Automatique de documents Hospitaliers (CoDeinE)